

TL;DR
Scaling remote engineering teams is not about location. It is about reducing system friction and improving engineering design. I have scaled teams across four continents. From this experience, I learned that reducing friction and building clarity, autonomy, alignment, and resilience matters more than any tool or process.
Framework: The Four Pillars: Clarity, Autonomy, Alignment, Resilience
Action: Reduce system friction before hiring. Measure maturity using DORA, SPACE, onboarding, and engagement scores.
Next step: Run a Remote Friction Audit and fix two blockers this quarter.
Introduction: Why Scaling Remote Engineering Teams Exposes System Issues
In a recent retrospective I led, two teams working remotely built different solutions for the same problem. Neither knew about the other’s work. Their intentions were good. Poor visibility, misaligned assumptions, and weak handoffs cost weeks of effort and months of technical debt. Scaling remote engineering teams did not cause this; it revealed it.
Distributed teams risk duplicated effort, architecture drift, and knowledge silos without proper systems.
The Four Pillars of Scaling Remote Engineering Teams
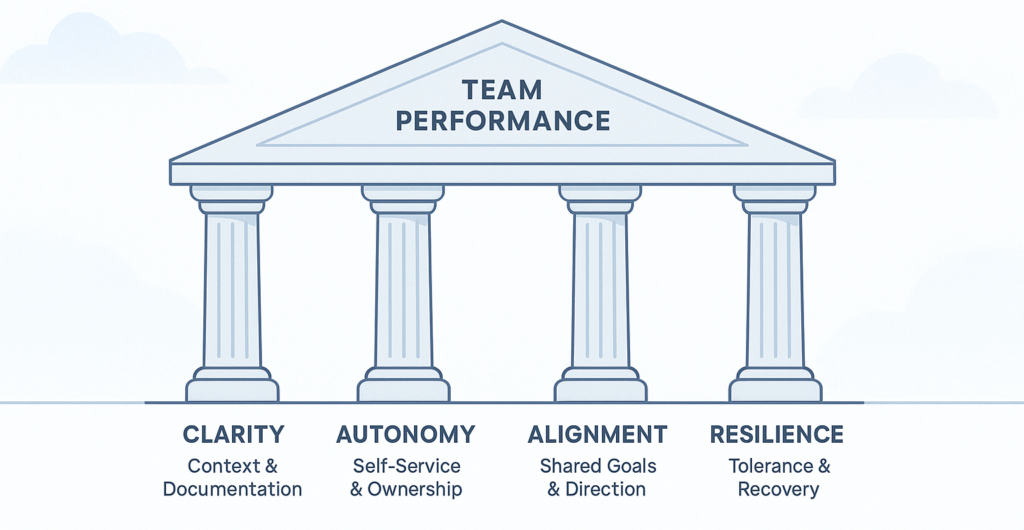
| Pillar | Outcome | Core Practice |
|---|---|---|
| Clarity | Shared context, fewer blockers | Write decisions down and document dependencies |
| Autonomy | Teams act without central approval | Build self-service and automate routine requests |
| Alignment | Consistent direction and design | Set clear, transparent goals and architectural maps |
| Resilience | Safety and continuity under stress | Invest in recovery processes, not just uptime |
Scaling remote engineering teams depends on visible work, removing blockers, aligned goals, and fast recovery.
System Friction Is the Main Barrier to Scaling Remote Engineering Teams
Friction kills performance, not distance. It appears as invisible blockers, unclear roles, missing documentation, or endless unproductive calls. Onboarding can take three days or three months depending on system visibility and reliability.
Example
A critical payments bug arose during European hours. Our asynchronous handoff allowed the US team to fix it within two hours of their morning standup. Without this process, delays would have lasted until the next overlap window.
Common Failure Patterns When Scaling Remote Engineering Teams
1. Duplicated Solutions
Failure: Teams build separate tools without knowledge of each other’s work.
Prevention: Require architectural reviews before new projects. Document systems centrally and make them searchable.
2. Async Overload and Sync Bottlenecks
Failure: Teams rely on endless Slack threads and frequent calls.
Prevention: Default to written, async-first collaboration. Reserve live meetings for design reviews, critical incidents, or major decisions.
3. Onboarding Gaps
Failure: New hires struggle to deploy or understand architecture from documentation.
Prevention: Maintain versioned, up-to-date onboarding guides. Use diagrams to explain dependencies.
4. Timezone Bias
Failure: Teams in minority zones feel excluded or slow down reviews.
Prevention: Rotate or remove recurring meetings. Require written input before live calls. Track review lag by region.
Example: In one team, Australian reviews lagged by days. Rotating code reviews weekly fixed this and improved inclusion.
5. Leadership Bottlenecks
Failure: Senior engineers delay pull requests, reviews, or architectural decisions.
Prevention: Empower teams with self-service platforms, standardise reviews, and monitor review times.
The Four Pillars in Action: Practical Examples
1. Make Work Visible
Anti-pattern: Meetings multiply but issues stay hidden in Slack.
Fix: Track decisions and progress in GitHub Projects. Record Loom updates. Written standups cut PR cycle time by over 25 percent. Onboarding time halved once documents became searchable.
2. Engineering Fundamentals
Anti-pattern: Knowledge trapped in individuals or private chats.
Fix: Version onboarding docs, enforce trunk-based development, and document feature flags. This enabled safe deployments across time zones. Time to first deployment dropped from weeks to days.
3. Async-First Workflows
Anti-pattern: Teams rely on live calls; reviews drag on.
Fix: Use pull request templates with context, assign reviewers clearly, add handoff comments. Track review lag to trigger follow-ups. Reserve live meetings for critical tasks.
4. Fix Systems Before Hiring
Anti-pattern: Adding headcount to broken workflows increases chaos.
Fix: Audit deployment frequency and lead time first. Use developer surveys and DORA value stream mapping (DORA Guide) to find bottlenecks. Fixing CI instability doubled throughput before new hires.
Platform Engineering: The Backbone of Scaling Remote Engineering Teams
Platform engineering is essential for distributed scale. In one transformation, internal developer platforms gave new engineers a safe sandbox from day one. Security, compliance, and pipelines were templated. This cut onboarding by a third and enabled production deployments within five days.
Industry example:
GitLab’s platform-first model supports thousands of contributors worldwide. Spotify’s Backstage unifies engineering across remote squads. Investing in platform teams and self-service infrastructure is the highest leverage move for remote CTOs.
Implementation Roadmap for Scaling Remote Engineering Teams
- Start a Remote Friction Audit
- Can new engineers understand architecture from documentation alone?
- Is every system and decision documented centrally?
- Can code be deployed from any region without local help?
- Do metrics show PR or review lag by region?
- Are onboarding guides current and versioned?
- Is incident learning visible to all?
- How is regulatory and security compliance shown?
- Pick one pillar and highest blocker
- Implement a specific fix (e.g., review templates, rollback runbooks).
- Measure impact within one sprint or quarter, then repeat.
- Track progress with DORA (lead time, deployment frequency, review lag), onboarding, and engagement scores
- Account for async reviews and timezone handoffs in lead time.
- Align deployment windows to reduce change failure rates.
Expected timeline: Most teams improve delivery and onboarding in one to two months; platform investments pay back in six to twelve months.
Cost, ROI, Regulatory, and Security Considerations
Remote scaling is an investment. Track total cost per engineer including tools and compliance overhead. Show ROI by reducing onboarding, increasing deployments, and improving engagement.
Address regulatory and security constraints early. Ensure remote work meets data sovereignty, audit, and privacy standards. Build automated policy and security reviews into platforms.
Long-Term Lens
Run friction audits quarterly or after major changes. Grow mentorship and leadership programmes as systems mature. Leadership and engineering must be designed and measured, not left to chance.
Further reading
- DORA Value Stream Mapping Guide – Workflow audits
- GitLab Remote Playbook – Remote best practices
- Backstage by Spotify – Platform engineering at scale
- SPACE Framework for Developer Productivity – Engagement metrics
Leave a Reply